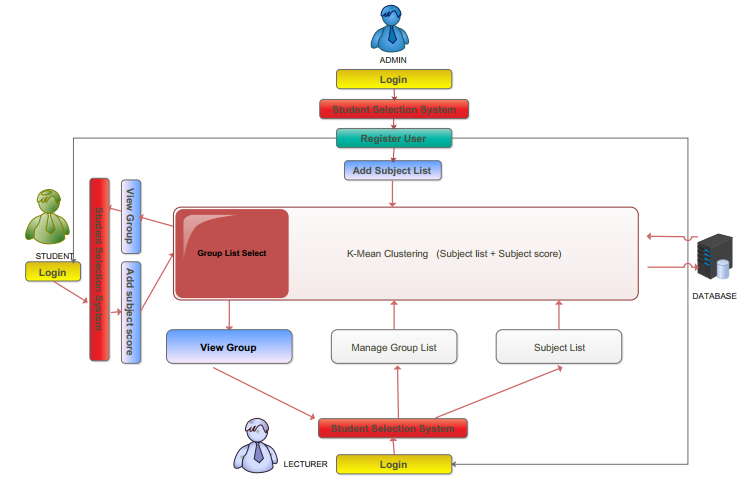
Student Grouping
SYSTEM
nik ahmad ridhuan bin nik ibrahim , Final Year Project , B.sc Internet Computing , University Sultan Zainal Abidin
Introduction
Student Selection Based On Academic Achievement System Using K-Means Clustering will be implemented to assist students and lecturers in addressing this problem.
In addition, K-Mean is a cluster method used to represent a group of students. In this system, the equations are based on the list of subjects as well as the number of students scores. K-Means is an algorithm of unorganized learning methods and attempts to be collected based on their equations. Total irregular scores of students will be collected based on the equation. In this system, the equations are based on the list of subjects as well as the number of students scores. |
Objective
|
Methodology
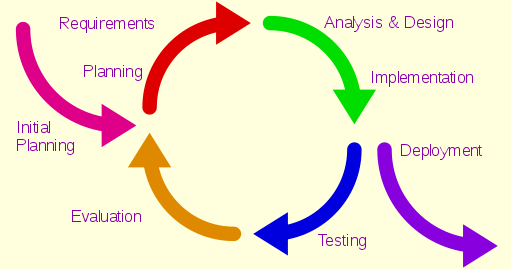
Iterative Model |